

You've probably had the experience: you mention something in conversation, and an hour later, an ad for exactly that thing appears in your feed. You think about buying new headphones, and suddenly every website shows you headphone ads. It feels like your phone is listening, like the algorithm can read your mind. The truth is simultaneously less creepy and more impressive. Recommendation algorithms don't need to read your mind because they've read enough minds already. By analyzing the behavior of millions of people, they can predict what you'll want with unsettling accuracy.
The feeling of being watched or listened to is remarkably widespread. A 2023 survey by the Pew Research Center found that a majority of Americans believe their phones are actively listening to their conversations for advertising purposes, despite no evidence that any major platform does this. The persistence of this belief, even among technically literate people, reveals something important: the experience of algorithmic prediction is so uncanny that surveillance feels like the only plausible explanation.
But the real explanation is both more mundane and more interesting. Understanding how recommendation systems actually work requires dismantling several intuitive assumptions about what these algorithms know, how they learn, and why they succeed as often as they do.
The Basic Mechanics of Recommendation
At their core, recommendation algorithms solve a prediction problem: given what we know about a user and an item, how likely is the user to engage with that item? "Engage" might mean click, watch, purchase, like, or any other measurable action. The algorithm's job is to rank potential items by predicted engagement and surface the most promising ones.
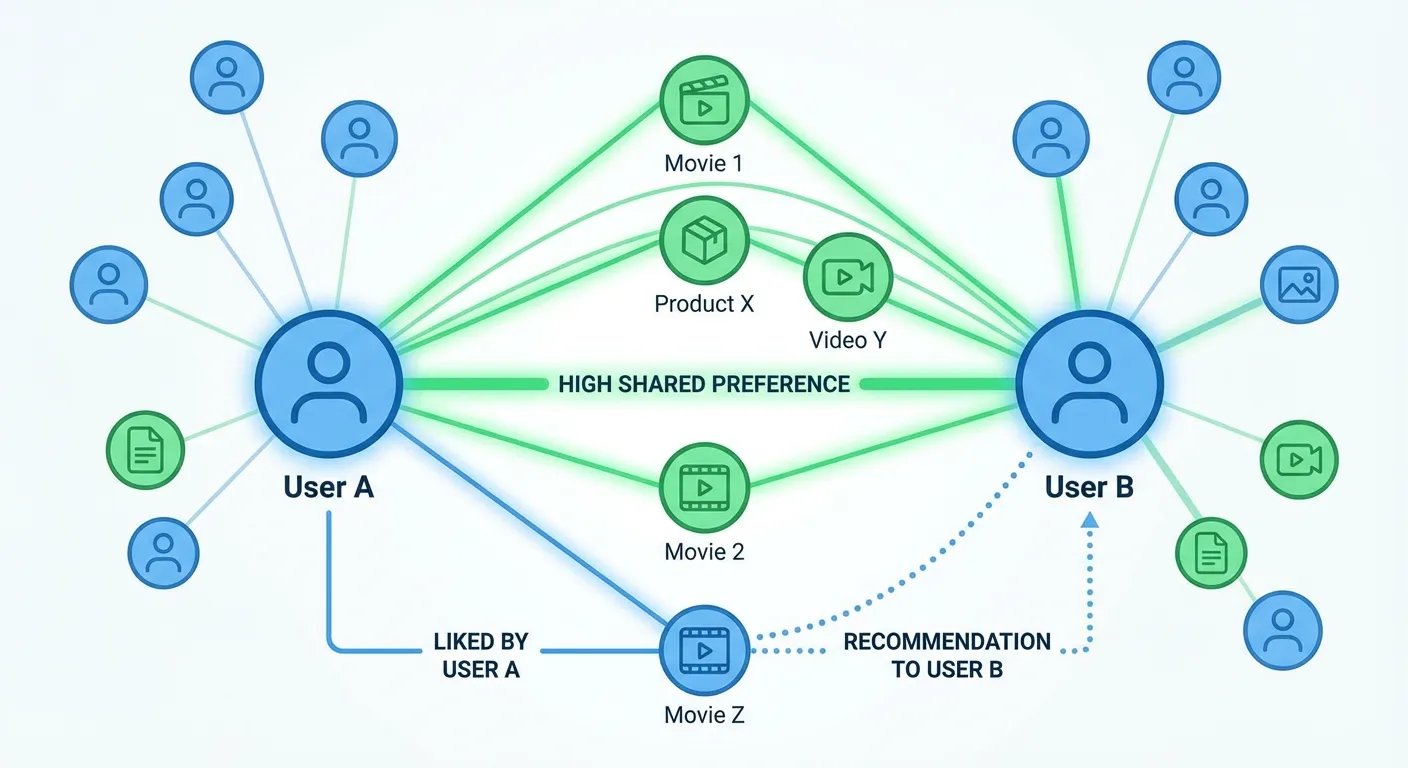
The earliest recommendation systems used straightforward approaches. Collaborative filtering, developed in the 1990s, works on a simple insight: if you and another person have liked many of the same things in the past, you'll probably like similar things in the future. Find users similar to you, look at what they've enjoyed that you haven't seen yet, and recommend those items. Amazon's "customers who bought this also bought" feature is collaborative filtering in its most visible form.
Content-based filtering takes a different approach: analyze the attributes of items you've enjoyed and recommend items with similar attributes. If you've watched several science fiction movies with strong female leads and philosophical themes, the system might recommend another film matching those characteristics, even if no similar user has watched both films.
Modern systems combine these approaches and add layers of sophistication. Matrix factorization techniques find hidden factors that explain patterns in user-item interactions, factors that might correspond to things like genre preferences or mood but emerge purely from data patterns without explicit labeling. Deep learning models, including the world models that are teaching AI to understand physics, can process multiple types of information simultaneously: your click history, the content of items, time of day, device type, and dozens of other signals. The result is prediction accuracy that would have seemed impossible just a decade ago.
Why It Feels Like Mind Reading
The mind-reading sensation comes from several sources, most of them traceable to cognitive biases rather than algorithmic capabilities. Confirmation bias, one of the many cognitive traps that distort our decision-making, plays a major role: we notice and remember the eerily accurate recommendations while forgetting the hundreds of irrelevant suggestions we ignored. That one time the algorithm seemed to know you were pregnant before you did sticks in memory; the thousand wrong guesses fade.
The timing of recommendations also creates false impressions. If you think about buying headphones and then see headphone ads, the natural assumption is causation. But you were probably exposed to something that put headphones in your mind, whether a friend's comment, a passing mention in a podcast, or seeing someone wearing distinctive earbuds. That same exposure may have triggered a search, a lingered glance at an ad, or some other measurable behavior that the algorithm detected. The thought didn't cause the ad; both the thought and the ad trace back to the same external trigger.
There's also the sheer volume of predictions being made. Tech platforms serve billions of recommendations daily. Even with modest accuracy rates, some percentage will seem uncannily well-timed. When an algorithm makes thousands of guesses about what you might want, statistical chance ensures some will land at moments that feel spooky. The ones that miss don't register; the ones that hit feel like telepathy.
Most importantly, humans are more predictable than we like to believe. Our tastes, interests, and behaviors follow patterns. We belong to demographic groups with shared characteristics. Our life circumstances, revealed through purchase history and browsing patterns, constrain and predict our needs. An expectant parent browses baby products, searches for pediatricians, and clicks on parenting articles in patterns that millions of parents have followed before. The algorithm doesn't know you're pregnant; it knows you're behaving like someone who is pregnant, and that's enough.
The Data That Makes Predictions Possible
The predictive power of recommendation algorithms depends on data, massive amounts of it, collected across every digital interaction. Every search query, every click, every pause while scrolling, every purchase, and every abandonment of a shopping cart becomes a data point. Aggregated across billions of users, these points reveal patterns invisible to individual observation.
Consider what a single platform like Google knows about its users. Search history reveals interests, concerns, and intentions. Location data shows where you go, how long you stay, and what routes you take. Gmail content, if scanned, reveals purchases, travel plans, and social connections. YouTube viewing patterns indicate what captures your attention and for how long. Calendar entries show how you structure your time. Chrome browsing data extends this visibility across the entire web. Combined, these signals create a behavioral profile of remarkable depth.
Facebook and Meta's properties aggregate social connections, political views, relationship status, life events, and the photos you upload and are tagged in. Amazon knows your purchase history, wish lists, browsing patterns, and how price changes affect your buying decisions. Netflix knows not just what you watch but where you pause, rewind, and stop watching.
When these data streams combine, whether through explicit data sharing, tracking cookies, or device fingerprinting, the resulting profiles become strikingly predictive. A famous 2012 study by psychologist Michal Kosinski and colleagues at Cambridge showed that Facebook likes alone could predict personality traits, IQ, sexuality, and political views with surprising accuracy. The data available to platforms today is orders of magnitude richer.
The Feedback Loop Problem
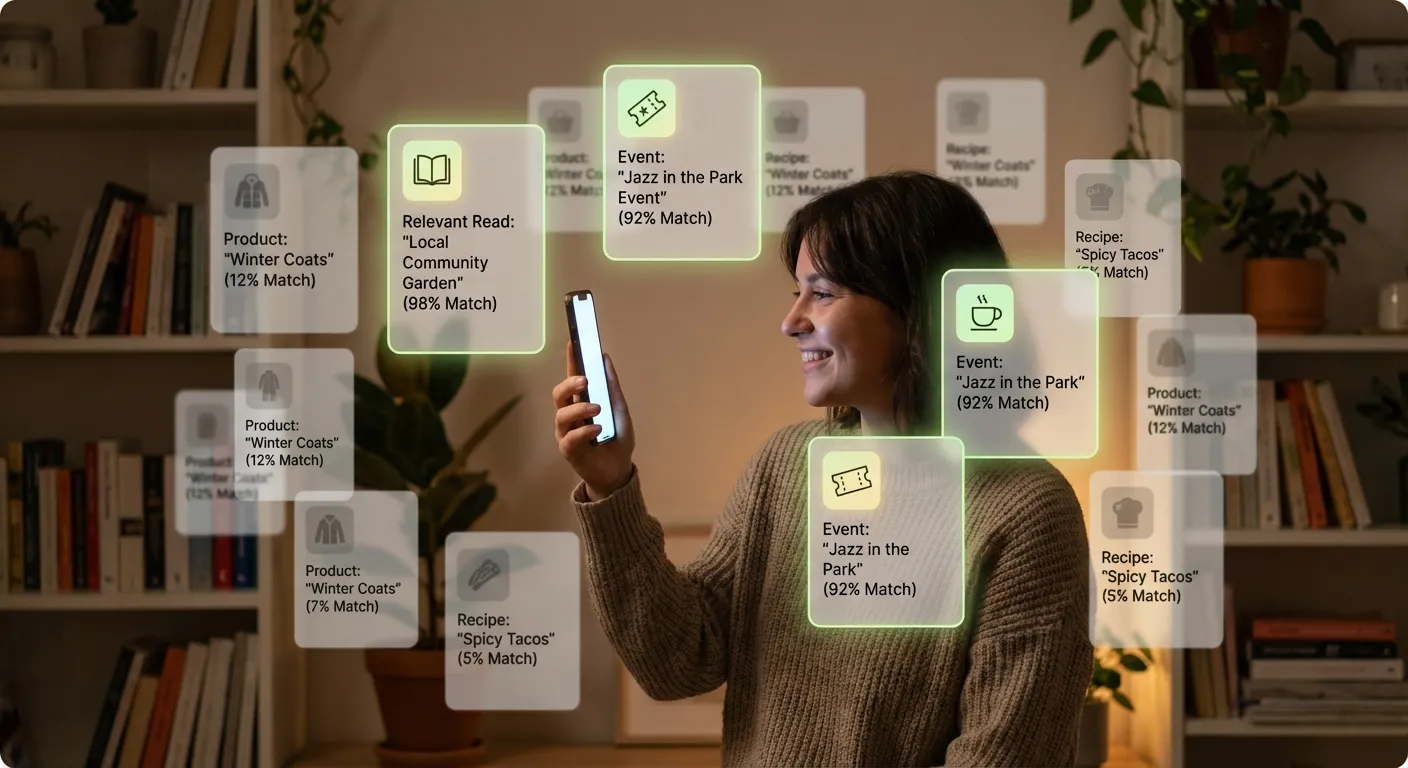
Recommendation algorithms don't just predict preferences; they shape them. When a system shows you content it predicts you'll engage with, and you do engage with it, the system learns that its prediction was correct and makes similar recommendations in the future. This creates a feedback loop where the algorithm increasingly shows you more of what it already knows you'll click, potentially narrowing your exposure to new ideas and perspectives.
This narrowing effect is most discussed in the context of political polarization and filter bubbles. If you engage with politically charged content from one perspective, the algorithm learns to show you more content from that perspective. Your feed becomes an echo chamber where your existing views are reinforced and opposing views rarely appear. The algorithm isn't trying to polarize you; it's trying to maximize engagement, and engagement happens to be maximized by confirming existing beliefs.
Similar dynamics affect other domains. Musical taste can calcify as streaming services recommend variations on what you've already heard rather than challenging you with unfamiliar genres. Shopping recommendations can lock you into brand loyalties by consistently surfacing familiar options. News feeds can create narrow information environments where certain topics are omnipresent and others invisible.
The platforms are aware of these concerns and have experimented with various interventions: diversity injections that deliberately introduce less-predicted content, exploration bonuses that reward clicks on unfamiliar items, and explicit user controls for broadening recommendations. But these interventions work against the core optimization target of maximizing engagement. Content that breaks patterns often performs worse by immediate metrics, even if it might serve users' longer-term interests.
The Limits of Algorithmic Understanding
For all their predictive power, recommendation algorithms don't understand anything in the human sense. They identify patterns in behavior without grasping the meaning of that behavior. The system that recommends grief counseling resources after detecting patterns consistent with bereavement doesn't understand death or loss; it has learned that certain behavioral signatures correlate with certain content preferences.
This mechanical nature leads to well-documented failures. Algorithms recommend content to people in crisis that deepens rather than alleviates their distress. They serve ads for baby products to parents who have experienced miscarriage. They suggest connecting with people you're trying to avoid. They recommend increasingly extreme content to users who have shown interest in fringe topics. These failures aren't bugs in the system; they're predictable consequences of optimizing for engagement without understanding context or consequence.
The algorithms also inherit and amplify biases present in their training data. If historical patterns show that certain demographic groups clicked on certain content, the algorithm will reproduce and reinforce those patterns. Research has documented discriminatory outcomes in job ads, housing ads, and lending recommendations traced to algorithmic systems reflecting historical biases.
Improving these systems requires more than better algorithms. It requires careful consideration of what outcomes we're optimizing for, what data we're training on, and what safeguards we're building in. The current generation of recommendation systems optimizes primarily for engagement, a metric that aligns imperfectly with user welfare, social benefit, or even advertiser interests in many cases.
The Fundamental Shift
Recommendation algorithms represent something genuinely new in human experience: systems that can predict individual behavior with high accuracy by aggregating the behavior of billions. The feeling of being read is not paranoia; these systems do detect patterns in your behavior that you might not consciously recognize yourself. The question is what we do with that knowledge.
One emerging response is regulatory. The European Union's AI Act, which took effect in stages beginning in 2024, requires that high-risk recommendation systems provide transparency about how they generate suggestions. California's proposed Algorithmic Accountability Act would mandate impact assessments for systems that influence access to housing, employment, or credit. These frameworks treat the prediction problem as a governance challenge: not how to stop algorithms from predicting, but how to ensure those predictions serve the people they affect.
Another response is architectural. A growing movement in platform design argues for "user-sovereign" recommendation, systems where the user controls the optimization target rather than the platform. Instead of maximizing engagement, these systems let users specify goals like "show me diverse perspectives" or "help me discover new genres." Early implementations on platforms like Mastodon and Bluesky suggest that users who control their own algorithms report higher satisfaction and less of the narrowing effect that engagement-optimized feeds produce.
Perhaps the most important response is personal. Knowing that these systems succeed through pattern aggregation rather than individual surveillance changes the nature of the privacy concern. The threat is not that someone is watching you specifically; it is that your behavior is legible to statistical models trained on billions of others. This legibility is not something you can opt out of entirely, because it derives from the regularities in human behavior itself. But you can become a more intentional participant, varying your patterns deliberately, auditing your own digital habits, and choosing platforms whose incentives align with your interests rather than against them.
The technology will only grow more sophisticated. The next generation of recommendation systems, built on large language models and multimodal AI, will incorporate not just clicks and purchases but tone of voice, facial expression, and even physiological signals from wearable devices. The gap between prediction and understanding will remain, but the predictions will become more granular and harder to distinguish from genuine comprehension. Meeting that future wisely requires clarity now about what these systems actually are, and what they are not.